Binary prediction using the logit function made from scratch
Logistic Regression is one of many supervised machine learning algorithms, just like Linear Regression. Instead of predicting a continuous value, it predicts the probability of an event happening, or something is true or false. So, this algorithms is mostly used for binary classification problems. Here are the use cases of Logistic Regression:
However, it also has the same limitations as Linear Regression, such as:
First, Logistic Regression still uses Linear Equation used in Linear Regression, and it’s expressed as:
Second, we are going to need Sigmoid function. This funciton’s sole job is to predict by converting the output of the linear equation into a probability value between and .
where . Then the sigmoid function can be rewritten as:
After acquiring the probability value from the Sigmoid function, we can use a threshold value to classify into one or another. To generalize, we can use the following equation to predict the probability of an event occurring:
Once we have the probability of an event occuring, we then use a threshold value to round up the probability value to either or . If , then the data is classified as , otherwise it is classified as .
Similar to what we did in the Linear Regression post, we need to estimate the best and using the Gradient Descent algorithm. What the Gradient Descent algorithm does is to update the and values based on the cost function and the learning rate.
This example is just a simple linear model, we are going to use the following equations to update intercept and coefficient:
where is the learning rate, is the -th parameter, is the cost function, and is the -th feature.
Since we only have and , we can simplify the equation above to:
First things first, we need to import the necessary libraries.
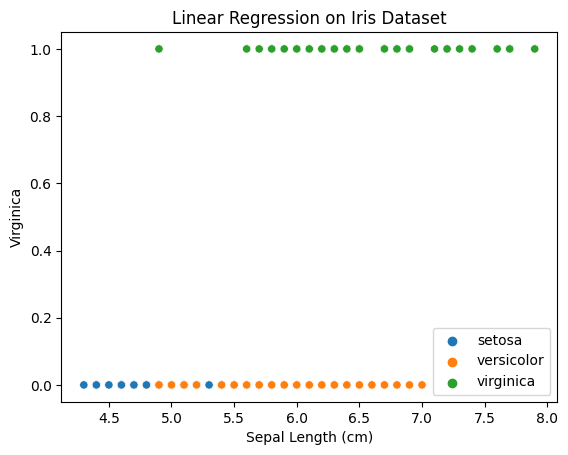
from sklearn.datasets import load_irisimport matplotlib.pyplot as pltimport seaborn as snsimport numpy as npSay that we only have a feature , the sepal length, and we want to determine the instance is a Virginica or not. Let’s prepare the data.
iris = load_iris()sepal_length = iris.data[:, 0]target = iris.target
is_virginica_dict = {0: 0, 1: 0, 2: 1}is_virginica = np.array([is_virginica_dict[i] for i in target])
species_dict = {0: 'setosa', 1: 'versicolor', 2: 'virginica'}species_name = np.array([species_dict[i] for i in target]) You might be wondering why we have is_virginica_dict.
I need that variable to separate the data so that some data sit at the bottom of the plot and some sit at the top of the plot.
So let’s add a line like we did in the Linear Regression post with as the intercept and as the coefficient.
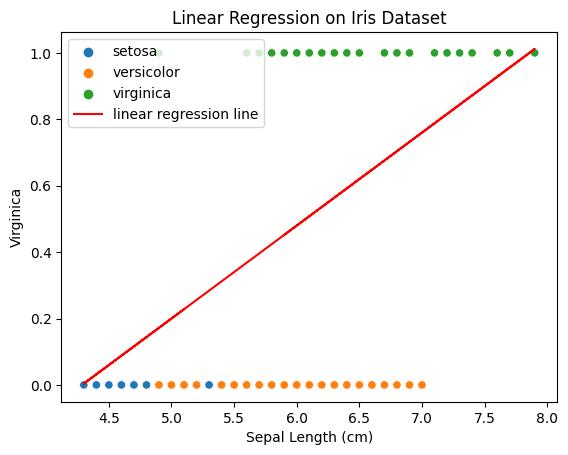
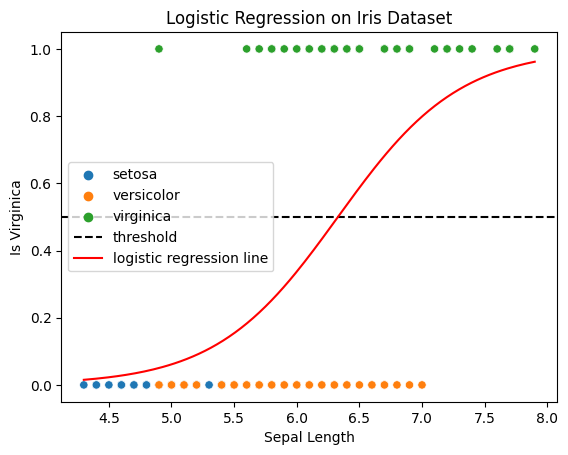
It’s clear that our data do not follow the pattern that the straight line is showing in the graph. Thus, we need to use Sigmoid function to bend the line, so that the line would look like this:
def accuracy(y_pred, y): return np.sum(y_pred == y) / len(y)
def sigmoid(x): return 1 / (1 + np.exp(-x))
def linear_function(intercept, coefficient, x): return intercept + coefficient * x
def threshold(x): return np.where(x > 0.5, 1, 0)
def gradient_descent(x, y, epochs, alpha = 0.01): intercept, coefficient = -1.2, 0.28 # initial guess
for _ in range(epochs): y_pred = np.array( [ sigmoid( linear_function(intercept, coefficient, i) ) for i in x ] ) intercept = intercept - alpha * np.sum(y_pred - y) / len(y) coefficient = coefficient - alpha * np.sum((y_pred - y) * x) / len(y)
return intercept, coefficientLet’s train our model for times.
intercept, coefficient = gradient_descent(sepal_length, is_virginica, 100000)predicted_value = np.array([sigmoid(linear_function(intercept, coefficient, i)) for i in sepal_length])corrected_prediction = threshold(predicted_value)pred_acc = aaccuracy(corrected_prediction, is_virginica)
print(f'accuracy: {pred_acc:.4f}') # 0.8print(f'intercept: {intercept:.4f}') # -13.004847396222699print(f'coefficient: {coefficient:.4f}') # 2.0547824850027654Not bad, the accuracy is , with as the intercept and as the coefficient.
You can find the full code in this repository